[GCP] 구글 클라우드 플랫폼으로 분석 환경 무료로 만들기
Tensorflow을 활용한 딥러닝 분석 환경 구축
저와 같은 학생들에게 딥러닝을 공부하면서 가장 큰 문제는 컴퓨팅 능력일 것입니다.
큰 데이터를 활용해서 많은 노드와 여러 개의 레이어를 쌓은 신경망을 노트북의 보잘것없는 CPU로 학습하려고 하면 정말 오래 걸립니다.
그래서 꾸역꾸역 공개된 서버의 Jupyter Notebook을 활용해서 학습하더라도 기본적으로 몇 시간, 넘어서는 몇 일 동안 학습을 진행하는 모습에 가슴이 답답해져서 GCP를 이용하고자 마음 먹었습니다.
GCP(Google Cloud Platform)은 구글에서 Compute Engine, Storage, Network 등을 클라우드 환경에서 빌려 사용하고 사용한 만큼 금액을 지불하는 서비스입니다.
하지만 GCP를 처음 사용하는 이용자에게 $300의 크레딧을 제공하고 이를 이용하여 무료로 GCP를 이용할 수 있게 합니다!
또한 이 크레딧은 계정마다 지급하며, 구글 계정은 여러개를 만들 수 있습니다.
그래서 지금부터 GCP를 이용하여 간단하게 Tensorflow-gpu를 사용할 수 있는 분석 환경을 구축하는 방법을 알아보겠습니다.
1. GCP 활성화
GCP 링크 : https://console.cloud.google.com
사이트에 접속하면 우측 상단에 다음과 같이 무료로 크레딧을 줍니다.
그리고 진행되는 사항에 따라 이름, 도시, 주소, 전화번호, 신용카드 정보를 입력하시면 됩니다.
오른쪽에서도 안내하는 것처럼 30일이 지난다고 해서 여타 사이트(Coursera 등)와 같이 꼼수를 부려 자동 결제는 되지 않으니 안심하셔도 될 것 같습니다.
2. GPU 자원 할당 요청
CPU와 메모리, 저장 공간 등은 GCP를 활성화하면 바로 할당 받을 수 있지만, GPU 자원은 별도의 할당 요청을 통해 할당을 받아야 합니다.
이번에는 GPU 중 그나마 가격이 저렴한 NVIDIA의 Tesla K80 GPU를 할당 받아보겠습니다.
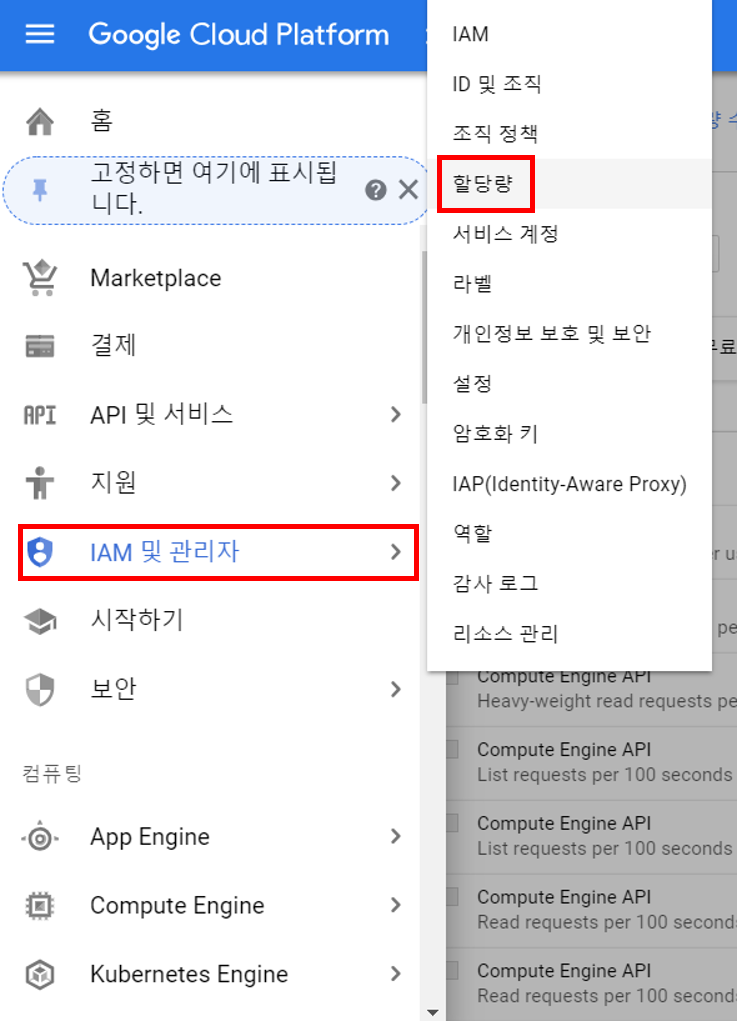
우선 위와 같이 좌측 상단의 네비게이션 바를 선택하여 메뉴 창을 여시고, ‘IAM 및 관리자’ 카테고리의 할당량을 선택해줍니다.
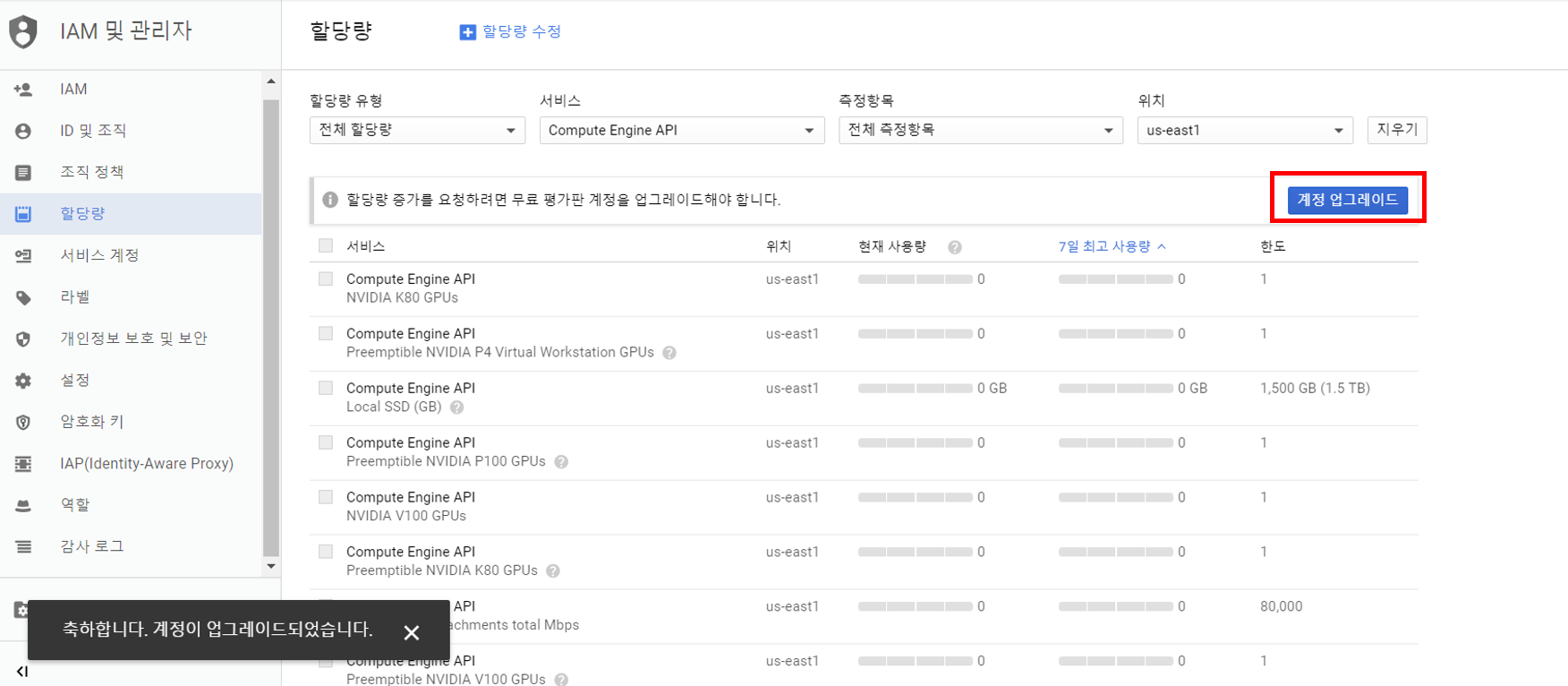
할당량 증가를 요청하려면 업그레이드 해야한다고 나옵니다.
하지만 계정 업그레이드 버튼을 클릭만 하면 위와 같이 계정이 업그레이드 됩니다! (왜 하라는건지?)
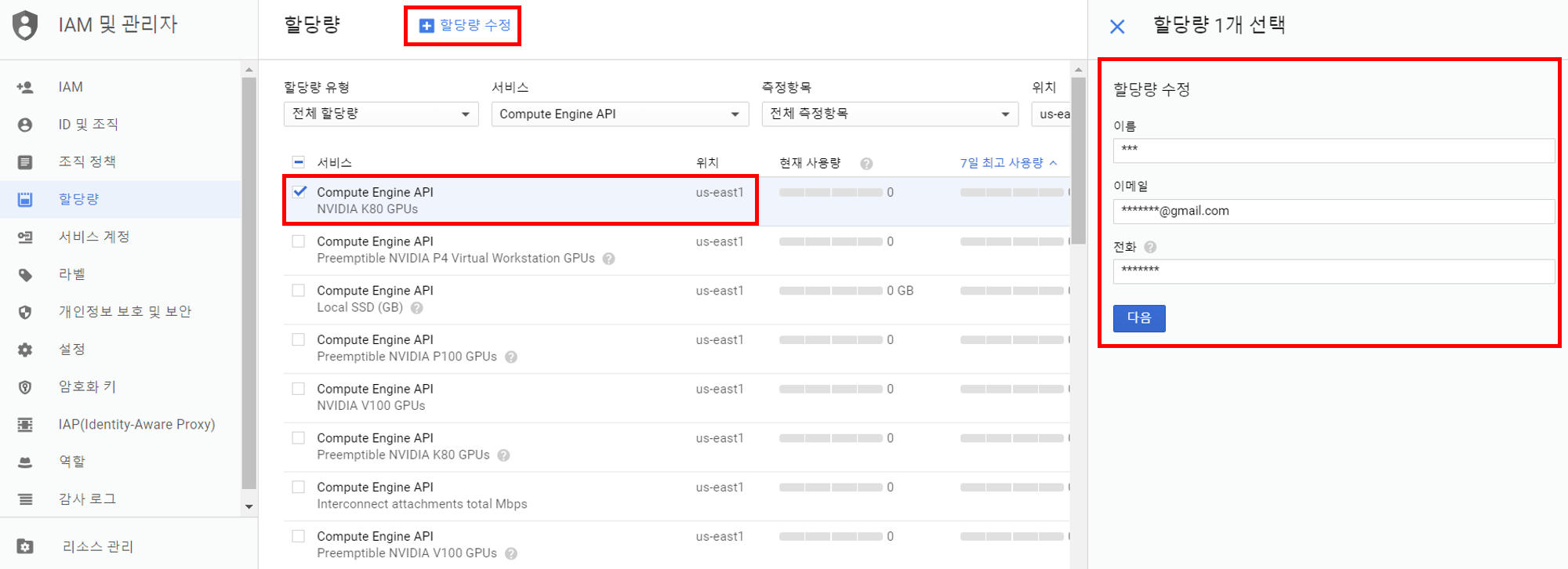
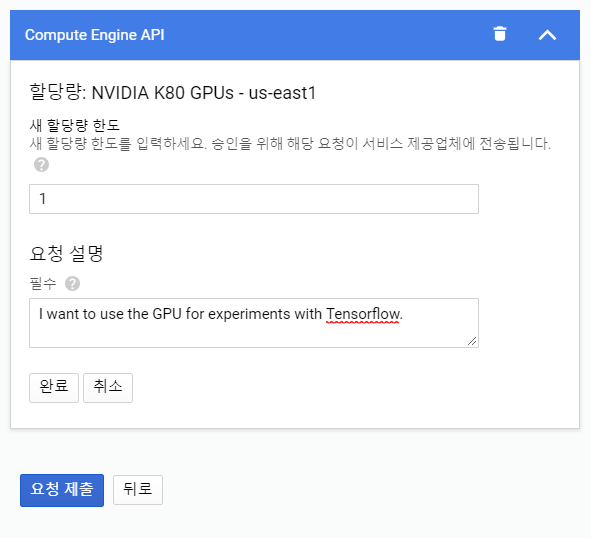
상단의 위치를 us-east1으로 변경하고 할당량을 요청할 K80을 클릭하여 활성화 후 +할당량 수정 을 클릭합니다. (다른 위치여도 상관은 없습니다만, K80 GPU가 존재하고 상대적으로 가격이 저렴한 위치라 골랐습니다)
혹시 위치에서 글로벌만 나타나시는 분은 3번의 Compute Engine을 클릭하신 후 되돌아오셔서 다시 해보시길 바랍니다.
이후 할당량을 1개로 설정하고 GPU를 요청하는 이유를 적으시면 되는데, 저는 Tensorflow 실험을 위해 필요하다고 하였습니다.
메일을 통해 할당되었다고 답변이 오는데 평일 기준, 1일 정도가 소모되었습니다.
첫 계정을 사용할 때는 현재 할당량이 0 이었으나, 포스팅을 위해 계정을 추가로 생성하였더니 현재 할당량이 초기부터 1으로 되어있네요. 만약, 현재 할당량이 1로 되어있다면 추가로 요청을 하지 않아도 됩니다.
3. Compute Engine VM 생성
이제 컴퓨터 자원을 할당받고, VM(가상머신)을 만들어야 합니다.
VM을 만드는 이유는 할당 받은 컴퓨터 자원을 효율적으로 분배하여 사용하고, 어느 환경에서도 접속할 수 있도록 해주기 떄문입니다.
VM 인스턴스를 생성해보겠습니다.
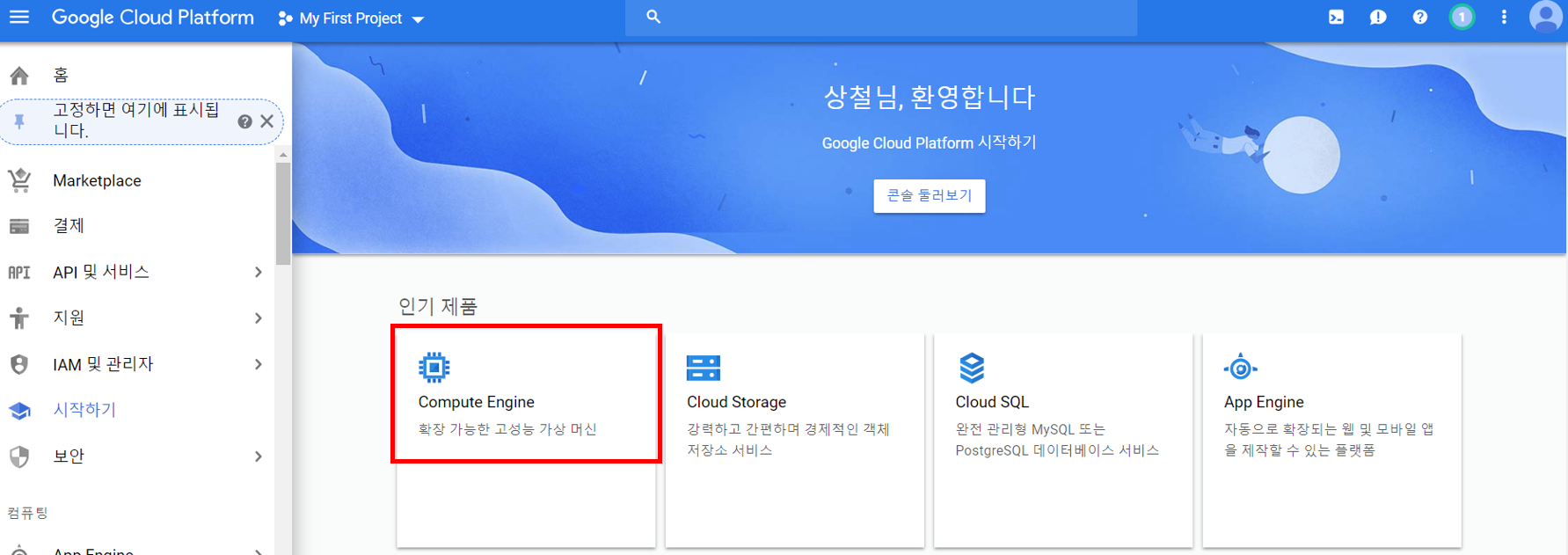
위와 같은 창에서 Compute Engine을 선택합니다. 만약 이 창이 뜨지 않는다면, 좌측 상단의 메뉴 창을 선택하고 Compute Engine을 선택하면 됩니다.
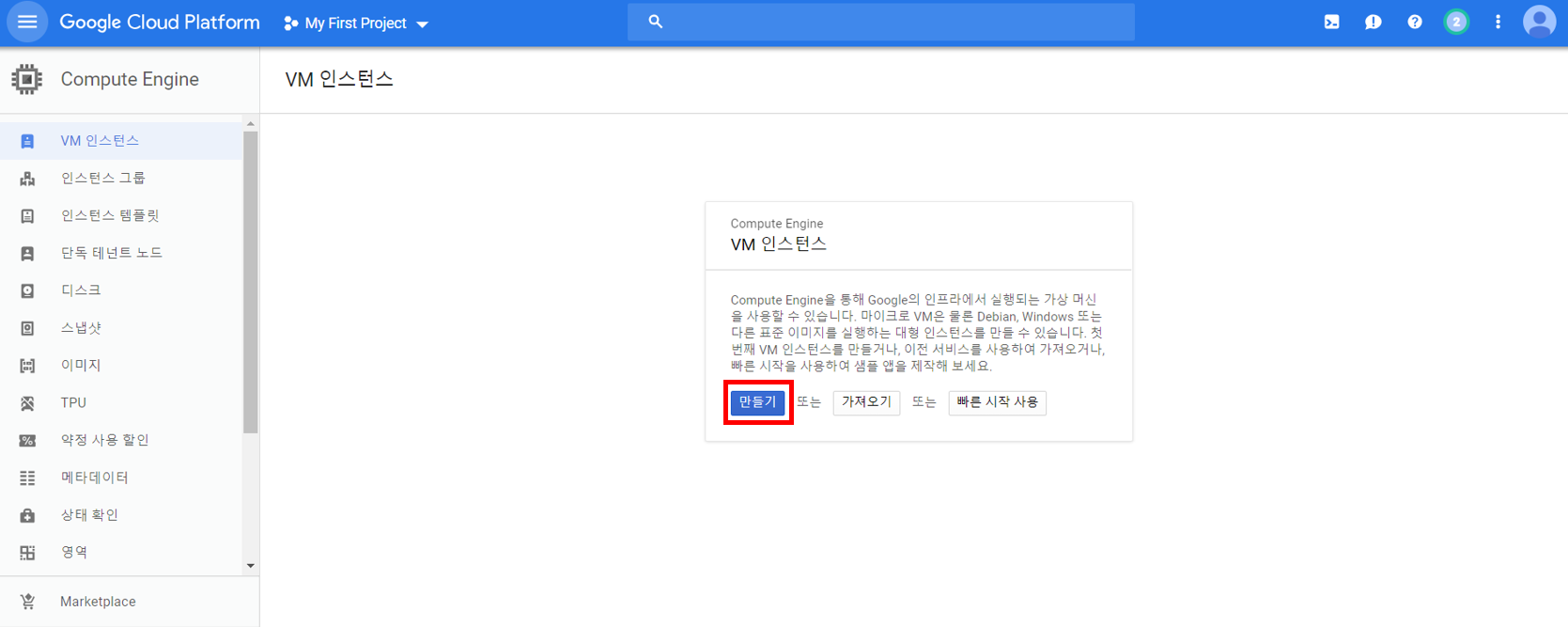
VM 인스턴스를 만들어줍시다.
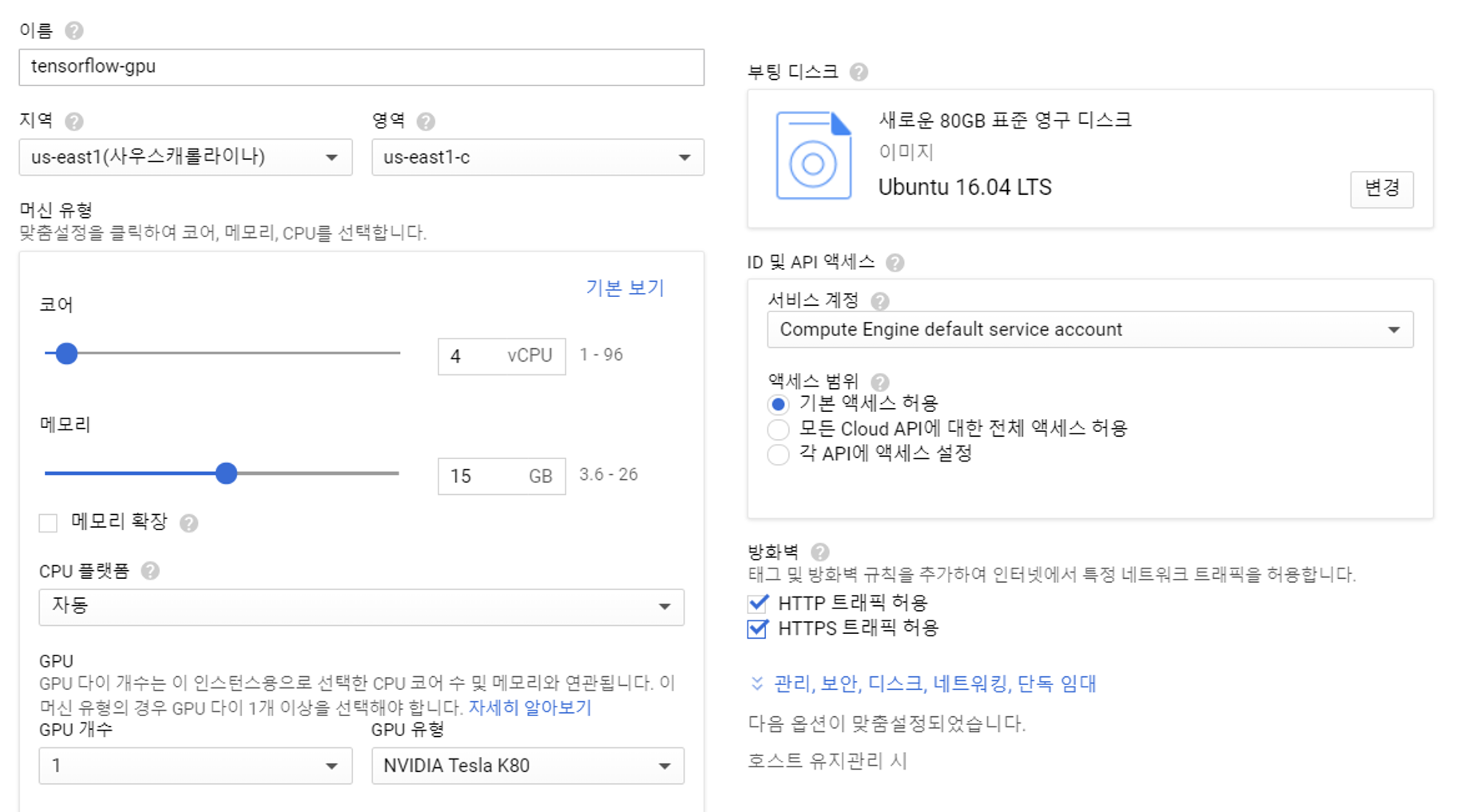
저는 위와 같이 설정하였습니다.
코어와 메모리는 원하시는 만큼 설정하시면 됩니다. 다만 자원이 많아지고 성능을 향상시킬수록 시간 당 요금은 비싸지니 잘 선택하시기 바랍니다.
또한 GPU를 K80으로 할당하였고, 만약 K80 GPU가 선택사항에 없다면 다른 지역을 선택하시기 바랍니다.
OS는 가장 환경이 잘 구축되어있는 Ubuntu 16.04 LTS를 선택하였고, 디스크는 80GB를 할당하였습니다.
또한 방화벽에 HTTP/HTTPS 모두 트래픽 허용하였습니다.
이렇게 인스턴스를 생성하시면 모든 자원을 할당받아 가상머신을 생성하였습니다.
이 가상머신은 동작 중인 시간만큼 요금이 계산되기 때문에 사용하지 않는다면 끄는 것을 추천합니다.
4. VM에 GPU Driver 설치
지금까지 잘 따라오셨다면 컴퓨터 자원을 할당하여 생성한 VM에 리눅스인 Ubuntu 16.04 OS를 설치하셨을 것입니다. (다른 OS를 설치하여도 무방하지만 방법은 달라질 수 있습니다)
이제 VM에 할당한 GPU를 제대로 동작하도록 하기 위해서는 GPU Driver를 설치해야 하는데요, 우선 VM의 우분투 OS에 접근해보겠습니다.
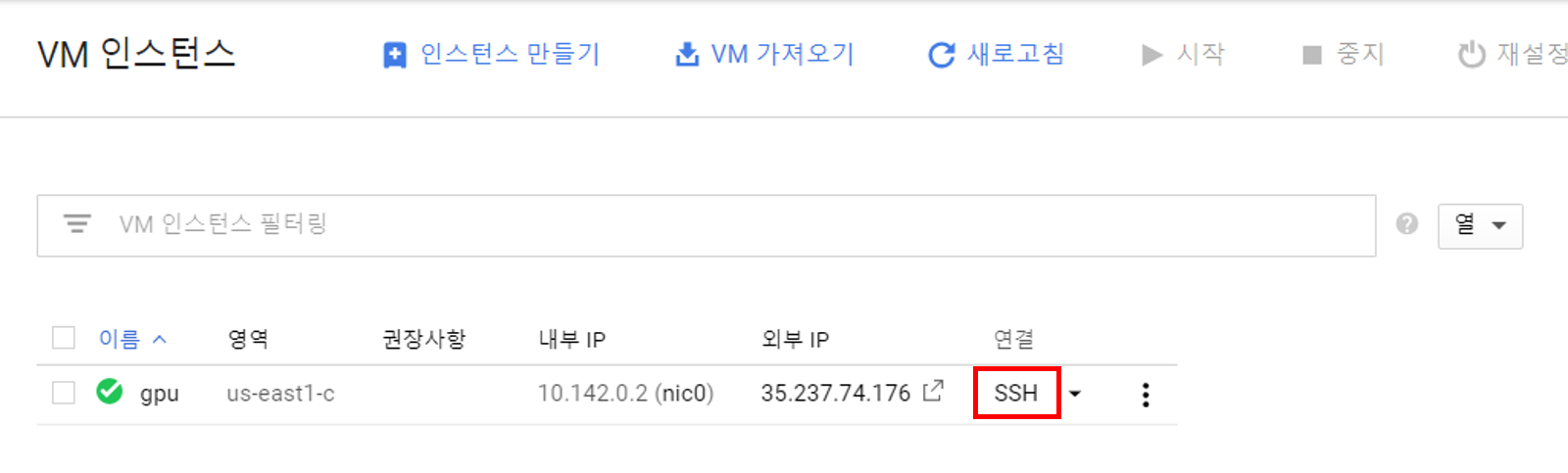
위와 같은 연결 탭에 보시면 SSH 연결, gcloud 명령 보기 등의 연결 방법이 있습니다. 가장 파워풀한 것은 Google Cloud SDK라고 하는 도구를 설치하여 gcloud 명령어로 연결하는 것이 좋지만, 이번에는 별도의 설치 없이 간단히 진행하기 위해 SSH 버튼을 클릭하여 브라우저에서 연결해보겠습니다.
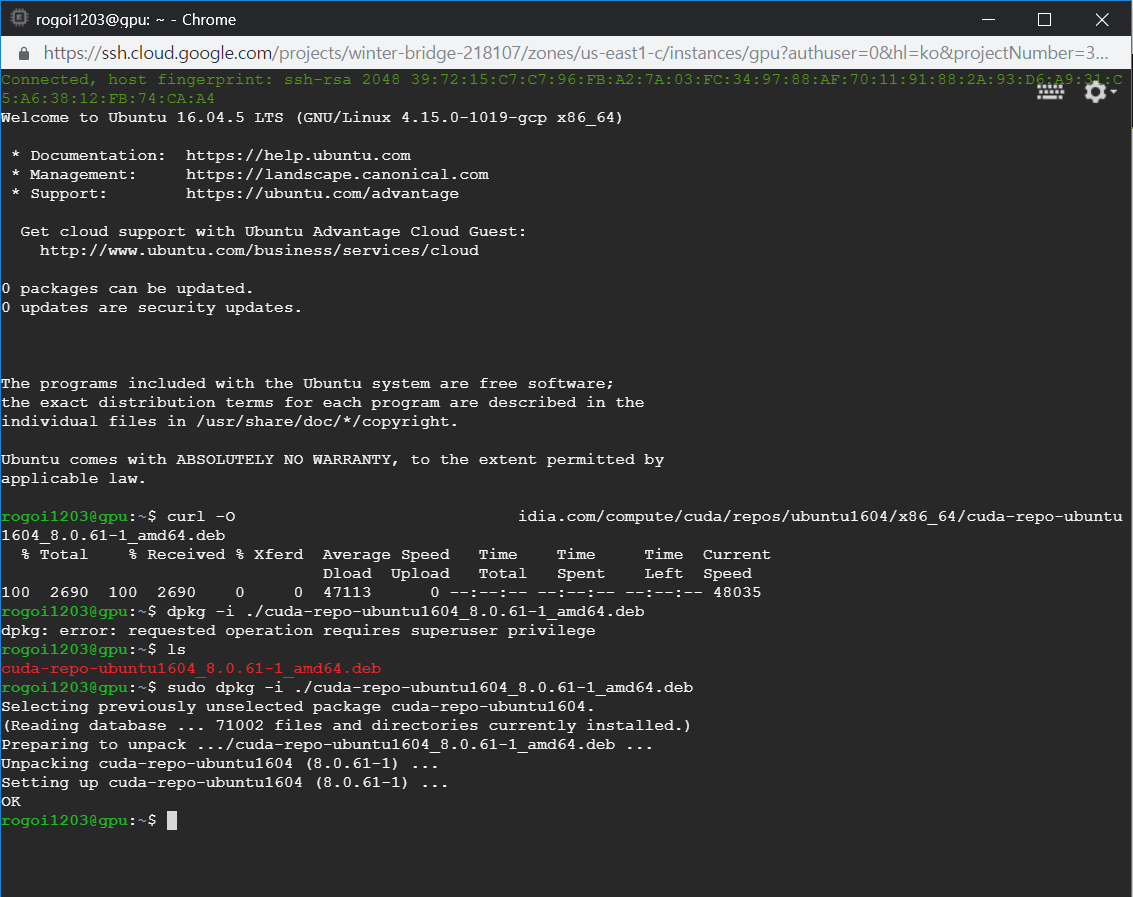
Welcome to Ubuntu 라는 말과 함께 연결이 되었습니다. 이제 CLI 환경에서 VM 인스턴스를 제어해야하는데요, GPU Driver를 설치하는 명령어는 다음과 같습니다. (여기서부터는 아래 참고문헌의 사이트에 기록된 내용을 가져온 것입니다)
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.0.176-1_amd64.deb
sudo dpkg -i ./cuda-repo-ubuntu1604_9.0.176-1_amd64.deb
sudo apt-get update
sudo apt-get install cuda-9-0 -y
각 명령어를 복사하여 붙여넣어주시면 됩니다. tensorflow 공식 사이트를 참고하면 CUDA Toolkit 9.0을 지원한다고 되어있기 때문에 9.0 버전을 설치하였습니다.
명령어의 의미가 궁금하시다면?
curl 명령어를 통해 nvidia 페이지의 ubuntu 16.04 전용 드라이브를 설치합니다. sudo(super user do) 명령어로 Super User(관리자)의 권한을 얻어서 dpkg(패키지 압축 해제) 명령어를 실행합니다. apt-get(우분투의 패키지 관리 도구)의 변경사항을 적용하고, cuda를 설치하는 과정입니다. 여기서 sudo 명령어를 사용하는 이유는 패키지의 관리 및 설치를 위해서는 관리자 권한이 필요하기 때문입니다.
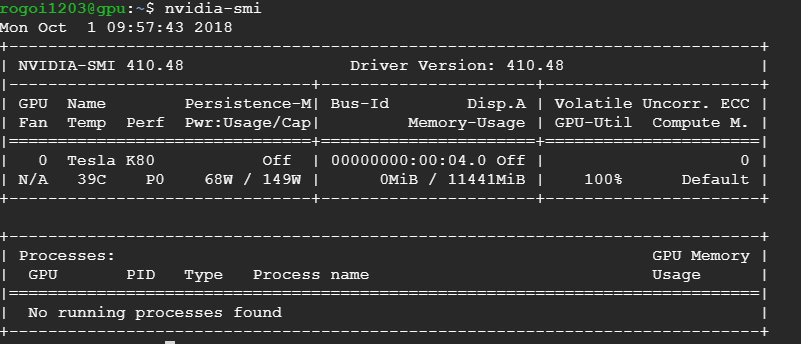
nvidia-smi
위 명령어를 실행시켰을 때, 위와 같이 Tesla K80 GPU에 관한 정보가 출력된다면 제대로 설치된 것입니다. 또한 우측 상단의 Driver Version이 400 이상의 최신 버전(18-10-01 기준)인지 확인하시기 바랍니다.
이제 cuDNN을 설치해야합니다.
참고한 많은 포스팅에서는 이 과정을 뛰어넘더군요. cuDNN이 tensorflow에 있어서 필수적인 패키지인 것은 확실한데, 왜 뛰어넘는 것인지는 잘 모르겠습니다. 실제로 cuDNN 설치 없이도 tensorflow가 설치가 되더군요. 하지만 설치한다고 문제가 되지는 않을 것이기에 저는 설치해서 진행해보봤습니다.
우선 Nvidia Developer Program에 회원가입 후 Join을 합니다. 그 후 cuDNN 다운로드 사이트에서 tensorflow에서 지원하는 버전 중 CUDA와 호환되는 파일을 받아야 합니다.
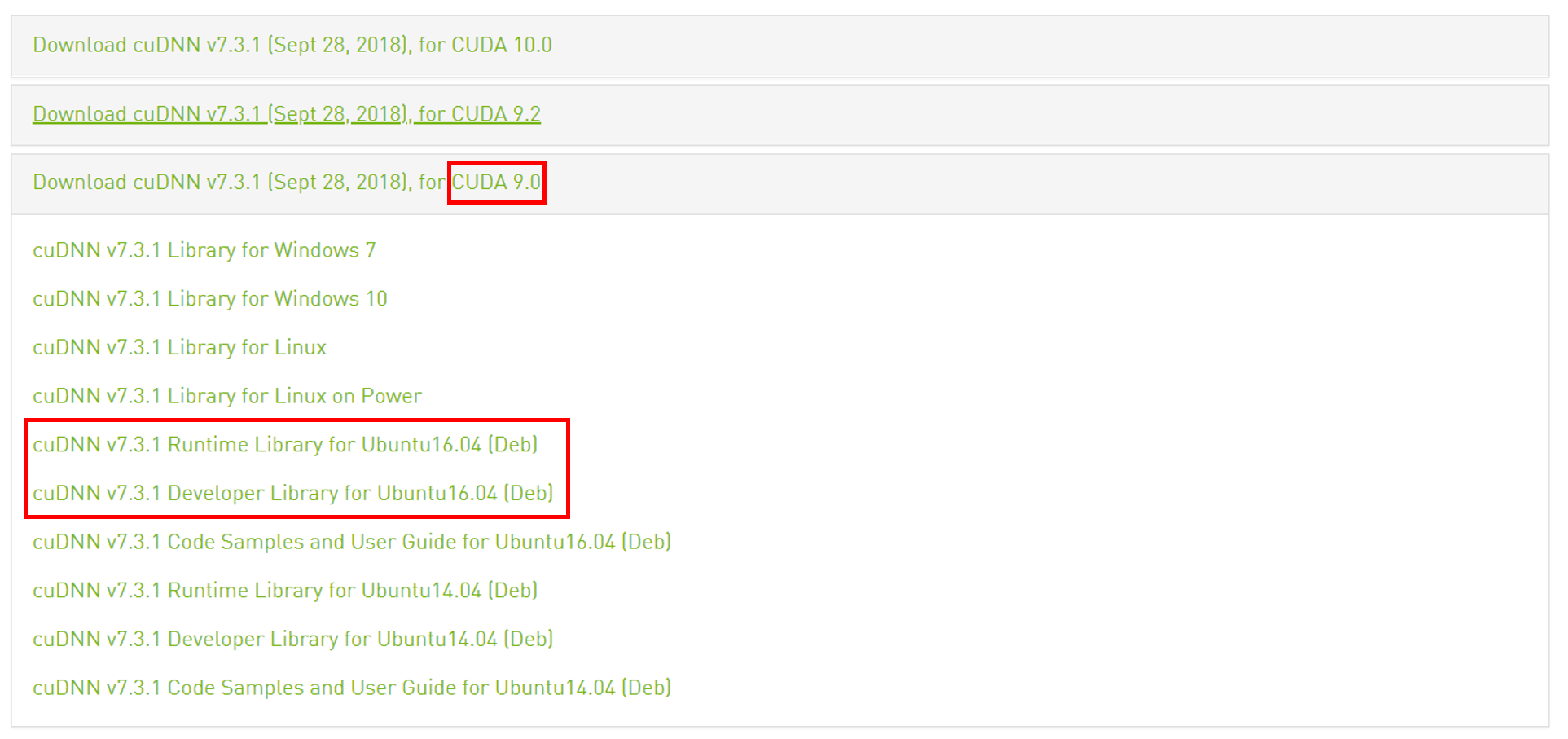
위와 같은 화면에서 Runtime 버전과 Developer 버전을 모두 받습니다.
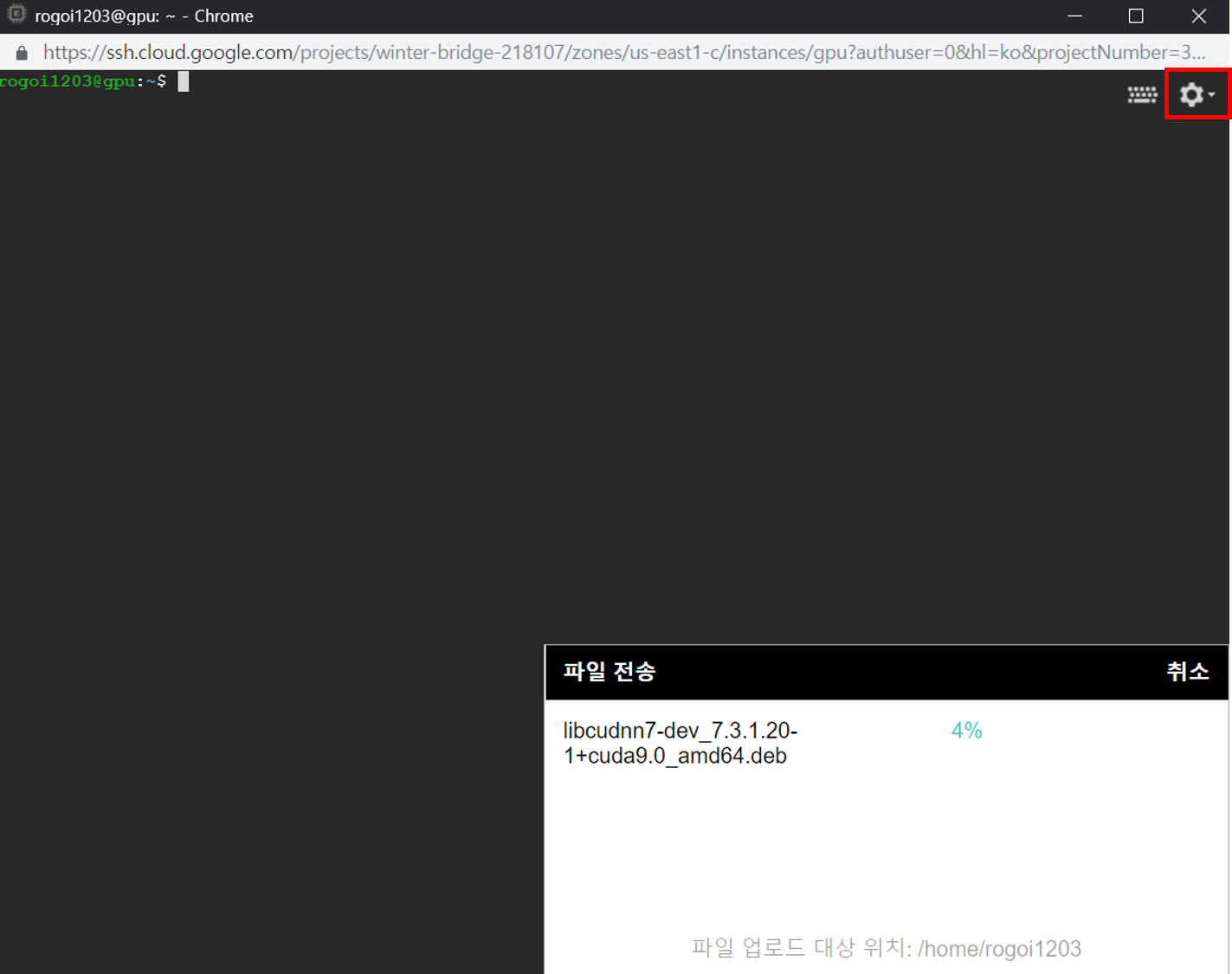
이제 인스턴스에 파일을 업로드해야 하는데, 우측 상단의 설정 아이콘을 클릭하면 파일 업로드가 있습니다. 두 파일 모두 업로드해야 합니다.
이후 다음 과정을 따라가시면 됩니다.
sudo dpkg -i libcudnn7*
패키지를 설치하고, CUDA의 기본 경로를 변경해주어야 합니다.
echo 'export CUDA_HOME=/usr/local/cuda' >> ~/.bashrc
echo 'export PATH=$PATH:$CUDA_HOME/bin' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
드라이버 설치가 드디어 완료되었습니다…
5. Docker 설치와 Jupyter Container 생성
조금만 더 하면 완성할 수 있습니다!!
#/bin/bash
# install packages to allow apt to use a repository over HTTPS:
sudo apt-get -y install \
apt-transport-https ca-certificates curl software-properties-common
# add Docker’s official GPG key:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# set up the Docker stable repository.
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# update the apt package index:
sudo apt-get -y update
# finally, install docker
sudo apt-get -y install docker-ce
 출처:
출처: 명령어를 한 줄씩 복사해서 실행시키면 됩니다. 오류 없이 제대로 실행된다면 docker라는 프로그램이 설치된 것인데요, docker는 가상화와 비슷하지만 조금 다른 개념입니다.
가상화와의 차이점이라면 별도의 가상화를 위한 공간을 할당하지 않아도 되고, 컴퓨터의 성능을 100%에 가깝게 이끌어낼 수 있습니다.
또한 자신이 원하는대로 OS를 구성하고 설정해둔 이미지를 컨테이너라는 개념으로 배포하여 깃허브를 통해 다운받을 수 있으며 컨테이너 이미지만 다운받았다면 불과 1분 이내에 컨테이너를 구성할 수 있다는 장점이 있습니다.
보다 자세한 내용은 도커와 관련된 포스팅이 아니기에 검색해보시는 걸 추천합니다.
우선 저희가 사용할 nvidia-docker 이미지를 다운받아보겠습니다.
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get -qq update
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
cat << EOF > Dockerfile.tensorflow_gpu_jupyter
FROM tensorflow/tensorflow:latest-gpu
RUN apt-get update && apt-get install -y python-opencv python-skimage git
RUN pip install requests ipywidgets seaborn
RUN jupyter nbextension enable --py widgetsnbextension
CMD ["/run_jupyter.sh", "--allow-root", "--NotebookApp.token=''", "--NotebookApp.password='sha1:a6179df3a1ce:383a2f049eb0fdf432e439b3c7170e21a3e07312'"]
EOF
sudo docker build -t tensorflow_gpu_jupyter -f Dockerfile.tensorflow_gpu_jupyter .
sudo nvidia-docker run -dit --restart unless-stopped -p 8888:8888 tensorflow_gpu_jupyter
위 내용은 어떤 분의 블로그의 내용 일부입니다.
저 코드를 정상적으로 모두 실행하면 되는데, 중간의 cat~EOF까지는 한 번에 복사하여 실행시키면 됩니다.
비밀번호는 jupyter로 초기화하였고 필요하시다면 IPython 환경에서 다음 코드를 실행시키고 비밀번호를 입력해서 나온 해쉬값을 중간의 NotebookApp.password=’’ 사이에 입력하시면 됩니다.
from IPython.lib import passwd
passwd()
여기까지 잘 따라오셨다면 환경을 모두 구축한 것입니다.
이제 네트워크를 고정IP로 변경하고 방화벽에서 tcp의 8888 포트만 개방하면 됩니다. 다시 GCP로 돌아와서 네비게이션 바의 ‘VPC 네트워크-외부IP주소’를 클릭합니다.
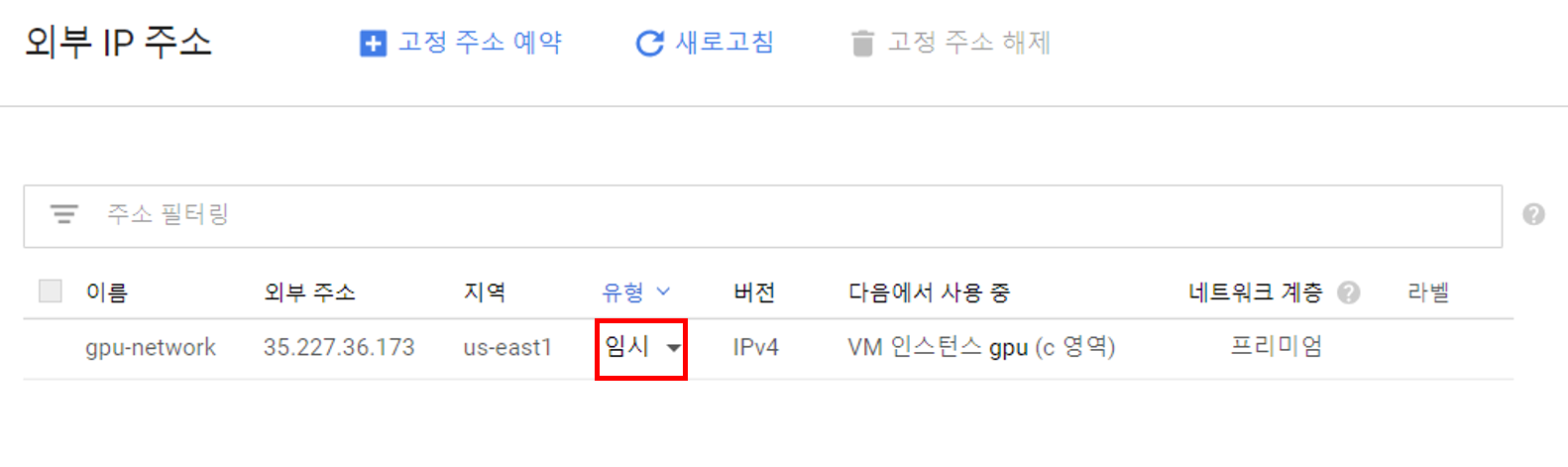
다음과 같이 VM 인스턴스의 IP가 임시로 되어있는 것을 고정으로 변경합니다. 이후 ‘VPC 네트워크-방화벽 규칙’로 접속합니다.
여기서도 ‘+방화벽 규칙 만들기’를 클릭하고 다음과 같이 설정하신 후 만들면 됩니다.
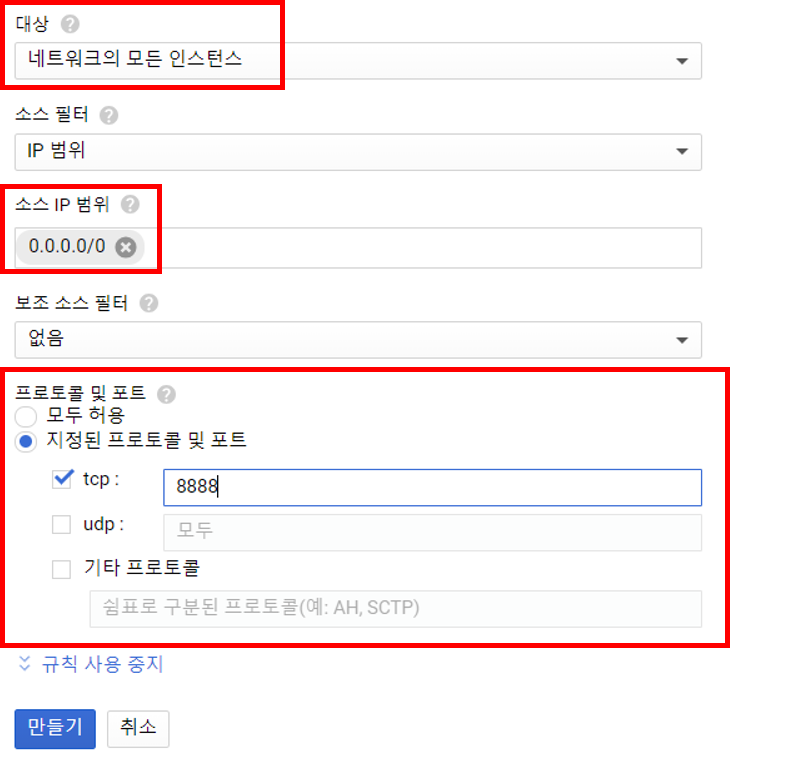
모든 환경 설정이 드디어 끝났습니다.
이제 Jupyter Notebook을 접속하기 위해
**http://<인스턴스 외부IP="">:8888** 로 접속하신 후, 비밀번호 jupyter를 입력하시면 정상적으로 접근이 될 것입니다.
인스턴스를 중지 후 재시작하였을 때, SSH로 접속하여
sudo nvidia-docker run -dit --restart unless-stopped -p 8888:8888 tensorflow_gpu_jupyter
명령어만 다시 실행시켜주시면 됩니다.
정말 긴 글이 되었고 시간도 오래 걸린 포스팅이었네요. 하지만 그 덕분에 저도 GCP와 tensorflow 환경 구축에 대해 좀 더 알아볼 수 있었습니다.
무엇보다 대부분의 GCP를 이용한 tensorflow 환경 구축 포스팅이 달랐고 버전 변경으로 인해 오류가 발생하여 저도 매번 고생하였습니다만… 제가 정리해둔 글을 통해 저도 새로 구축할 때 도움받을 수 있을 것 같습니다.
오류가 있다면 댓글로 알려주시기 바라고, 다음 포스팅에서는 GPU와 CPU 환경에서의 속도 차이를 알아보고 GPU가 제대로 세팅되었는지 보겠습니다. 또한 Instance를 실행시킬 때마다 명령어를 쳐야하는 귀찮음을 덜어보도록 하겠습니다.
출처
- http://www.morethantechnical.com/2018/01/27/an-automatic-tensorflow-cuda-docker-jupyter-machine-on-google-cloud-platform/
- https://github.com/NVIDIA/nvidia-docker
안녕하세요 :) 데이터 분석을 공부하는 블로그입니다.